Top 3 Products & Services
| 1. 2. 3. |
Dated: Dec. 08, 2012
Related Categories
Search Engine OptimizationTechnological Advances
Over the last 10 years Content based image retrieval (CBIR) or Content-based visual information retrieval (CBVIR) has been one on the most researched areas in the field of computer vision. The availability of large and steadily growing amounts of multimedia and visual data, and the development of the Internet create the need to make thematic approach methods that offer more than simple text-based queries or requests based on matching exact database fields.
It mean that images can be searched by their visual content and have a process made out of two phases: in the first step images are analyzed and inserted to the image database and after that they can be queried. There are two query-methods: query-by-example and query-by-memory. Users can selects an example image or select image features retrieved from memory (such as texture, shape, color, and spatial attributes) to define his query. For example you can choose a image of a human face and try to find similarly looking faces with similar shapes and/or color. You can mark the image as positive or negative samples to refine the search and find better results, because the query continues.
The text-based image retrieval exists from the late 1970s. By Banireddy Prasaad, Amar Gupta, Hoo-min Toong, and Stuart Madnick the first microcomputer-based image database retrieval system was created at MIT, in the '80s. The period between 1994–2000 can be thought of as the starting phase of research and development on image retrieval by content. In Smeulders et al. [2000] the progress made during this phase was summarized at a high level.
Many programs and tools have been created to formulate and make queries based on the audio or visual content and to aid searching large multimedia repositories. Even with that much effort, no major breakthrough has been made with respect to large varied databases with documents of differing sorts and with varying characteristics. Answers to many questions with respect to semantic descriptors, speed, or objective image interpretations are still without answer.
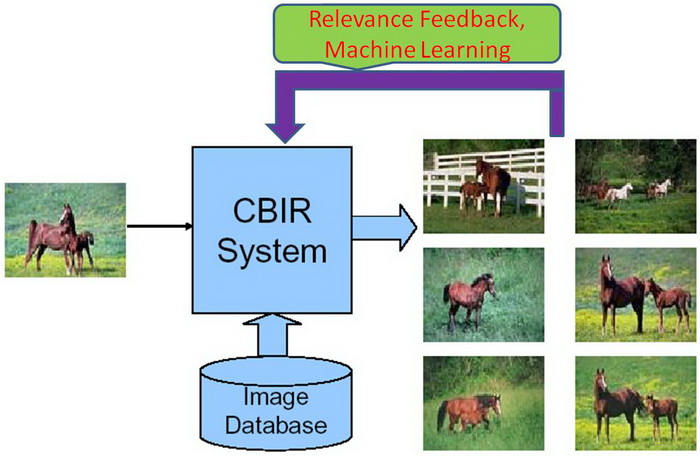 A image retrieval systems support one or more of these options :
A image retrieval systems support one or more of these options :
- search by sketch
- search by text
- search by example
- navigation with customized image categories
- random browsing
Here, we will choose some representative systems.
- QBIC standing for query by image content, is the first commercial content-based image retrieval system. Its system framework and techniques have deep effects on later image retrieval systems.
- Virage is a content-based image search engine developed at Virage Inc. Virage supports visual queries based on texture, and structure (object boundary information), color, and composition (color layout). Virage goes one step further than QBIC.
- RetrievalWare is a content-based image retrieval engine developed by Excalibur Technologies Corp. From earlier publications, we may see that its emphasis was in neural nets to image retrieval. It is a more recent search engine and it uses color layout, texture, color, shape, brightness, and aspect ratio of the image, as the query features.
- Photobook is a set of interactive tools for searching and browsing images researched at the MIT Media Lab. It contains three subbooks from which texture, shape, and face features are extracted, respectively. In each of the three subbooks users can query based on the corresponding features.
- VisualSEEk is a visual feature search engine and WebSEEk is a World Wide Web oriented image/text search engine, both of which are researched at Columbia University. Main research features are visual feature extractions from compressed domain and spatial relationship query of image regions. To speed up the retrieval process, they also developed binary tree based indexing algorithms.It supports queries based on both keywords and visual content.
- Netra is a prototype image retrieval system created in the UCSB Alexandria Digital Library project. It uses shape, texture, color, and spatial location information in the segmented image regions to search and retrieve similar regions from the existing database. Main research features of the Netra system are its edge flow-based region segmentation, Gabor filter based texture analysis , and neural net-based image thesaurus construction .
- MARS was developed at University of Illinois. It is different from other systems in both the research scope and the techniques that it uses.
In medicine digital images, are created in ever-increasing amounts and used for diagnostics and therapy. The Radiology Department of the University Hospital of Geneva alone made more than 12,000 images a day in 2002. In the medical field cardiology is the second largest producer of digital images, especially with videos of cardiac catheterization. Endoscopic videos can equally make huge quantities of data. With DICOM (digital imaging and communications in medicine), a standard for image communication has been set and the information about the patients can be saved with the actual images.
Potential uses for CBIR include:
- Military
- Retail catalogs
- Architectural and engineering design
- Crime prevention
- Geographical information and remote sensing systems
- Intellectual property
- Art collections
- Medical diagnosis
- Photograph archives
Data Scope
It is very important to understand the nature and scope of image data plays a key role in the complexity of image search system design. Factors like the diversity of user-base and expected user traffic for a search system also greatly influence the design. Besides that, search data can be classified into these categories:
- Archives - usually contain huge volumes of structured or semi-structured homogeneous data pertaining to specific topics.
- Domain-Specific Collection - this is a homogeneous collection providing approach to controlled users with very specific objectives.
- Enterprise Collection - a heterogeneous collection of images that is accessible to users within an organization’s intranet.
- Personal Collection - usually consists of a huge homogeneous collection and is usually small in size, in most of the cases it's accessible only to its owner.
- Web - World Wide Web images are available to everyone with an Internet connection. These image collections are semi-structured, non-homogeneous and massive in volume, and are usually stored in large disk arrays.
In the last decade there have been a fast increase in the size of digital image data. Everyday, both civilian and military equipment generates giga-bytes of images. However, we cannot access or make use of that information unless it is organized so as to allow effective browsing, searching, and retrieval.
Now that you've gotten free know-how on this topic, try to grow your skills even faster with online video training. Then finally, put these skills to the test and make a name for yourself by offering these skills to others by becoming a freelancer. There are literally 2000+ new projects that are posted every single freakin' day, no lie!
 Previous Article |  Next Article |