Top 3 Products & Services
| 1. 2. 3. |
Dated: Aug. 13, 2004
Related Categories
By Najmi
Abstract
This non-technical document is intended for the database administrators or database designers who are planning for data-replication or who want to understand it usage and its implementation on the ongoing database with respect to the application requirements.
This document includes the unified treatment of conflicts and errors, column-level tracking of changes, improved priority-conflict-resolution algorithm, added replica types and extended replication functionality exposed through out the available replication types.
Before diving into detail of data-replication, the paper focus some major issues that covers Data Replication, its usage, its planning, designing and implementation. It also listed the major available database servers for performing database replication.
Database Replication?
Database replication is a technique that is use to support multiple online or offline users of an application. Replication is the process of creating multiple copies of an application and its data to be used at different locations that are not always connected to each other.
Database replication is different from file replication, which essentially copies files. Replication checks the tables for updated data and moves the data from the source to the target systems while guaranteeing data coherency and consistency.
For example, a voucher created by a shop keeper can be transferred from one shop in Karachi to an Head Officein Dubai; and a sales force automation system replicates all purchase entries to the local sales 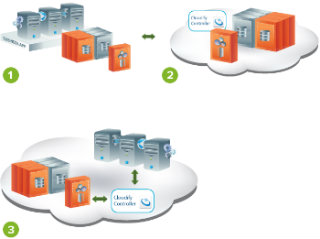 representative.
representative.
Why Replication?
The above goal from data replication can be fulfill by providing 24 hours online connected or distributed computing environment with high availability of optimal network providing the demand of data integrity too. The current challenge in the field of database management for administrators is to determine the best way for distributing large amount of data without connected to the server for the whole day.
Although once should not expect from a shop keeper or a saleperson having an average monthly revenue to be connected with the Head Office for the whole day. In such a case we use Data Replication that is a best way to distribute a large amount of data across the network in a timely fashion. Data Replication is almost supported by all major database vendors such as Microsoft Corp, Oracle Corp, Sybase Inc, Informix Software Inc, IBM Corp, and Computer Associates International Inc. These vendors have advanced replication technology, and once can build solid replication architectures by using these vendors.
Planning for Replication
Replication is a serious business, even If the user interface simplifies the implementation and administration, replication requires careful planning and analysis. It is important to have a thorough understanding of the mechanism of your database that uses replication. Managing a distributed database is vastly more difficult than managing a centralized database as it requires a lot of time for justifying and planning replication.
Before planning for replication we have to consider some major factors such as how quickly you need data synchronized across all sites. Budget for hardware, software, and communication services. Overall system-reliability requirements.
The best candidates for replication are applications that can tolerate some latency in data updates in exchange for a robust configuration that can allow updates from any replica and that supports users who are only occasionally connected. This flexibility means the system can work more effectively, potentially improving business performance.
Using flexible, low-cost, off-peak asynchronous communication links and asynchronous data duplication provides "real-time-enough" updates without the expense and vulnerability of full-time connections between all nodes. When the application's users are connected, it might be through a direct connection ona local area network (LAN) or wide area network (WAN), or through the Internet or an intranet. Data can be exchanged on a LAN, a WAN, or the Internet.
Designing database for Replication
Now, It is a time that we took some stuff in hands including an ERD of a Database, a pencil and a rubber, a coffee is also necessary as we are designing a database into a replicable format. As stated above replication requires careful planning and analysis so first we start from selecting the activities of different database servers. It is better to select at least 2 database servers that are: -
1. Main-Database also known as Head-Office and will act as a Data-Distributor
2. Subscriber-Database also known as Factory/Shop andwill act as a Data-Receiver.
Head-Office Published and Distribute the necessary data to its clients. The main purpose of the Head Office is to replicate the central data to its subscribers and to store all setup tables here, so that all setup entries are done at Head-Office and then replicated to its subscribers.
Rest of the Data-Servers are subscribers to the Head Office. Data will be replicated to the Head Office (actas a Publisher) first and then the Head Office (act as a Distributor) will replicate it to the subscriber. Any data from one subscriber will not be migrated to any other subscriber until and until it is not migrated to the Head Office first. This can be further depicted from the figure1 below: -
In such a case the Head Office can PUSH data toanother Data-Server and can PULL (get) data back from its Subscribers.
Conflict Resolution
In order to avoid conflict between identical values of different Data-Servers, we have to define a separate identity (identity-sequence) for each Data-Server, insuch a case the id does not match to the ids of the dependents tables which cause a major problem in parent-child relationship among tables. This can be depicted from the chart below
Data Sequence for the Data-Servers
HEAD-OFFICE has a seed of 1 and an increment of 2(odd, positive no)
FACTORY has a seed of 2 and an increment of 2 (even,positive no)
CUSTOMER has a seed of -1 and an increment of -2 (odd,negative no)
SUPPLIER has a seed of -2 and an increment of -2(even, negative no)
Managing Master Tables/ Setup Tables
Every application requires some data for few tables by default. These tables are categorizes into two further types: -
1. Base-Tables
2. Look-Up Tables
Base-Tables are those tables whose data can be added/updated/deleted thru application. Base-Tables are also migrated but initial lookup values will be same of each base-table for each Data-Server, such that at the time of each replication the initial values will not replicated due to the Primary-Keys conflict.
Lookup Tables are those tables whose data cannot be added/updated/deleted thru application. These tables are not migrated in order to increase migration latency.
Note: - Keep in mind that the Database structure of each Data-Server will be the same, except for the rules of generating Identical numbers.
Conclusion
Replication plays an important role of moving data quickly throughout the enterprise irrespective of the location. Whether you are building a data warehouse, corporate intranet, sales force automation tool, or any other distributed application; replication is a serious business, it needs a careful analysis and planning.
Before diving into replication once should categorized the database with respect to their project requirements. The above architecture is build on industry standards, and has been successfully implemented on one of the biggest ERP solution Business Patterns developed by ePatterns Pvt. Ltd after a research of 7 months.
Now that you've gotten free know-how on this topic, try to grow your skills even faster with online video training. Then finally, put these skills to the test and make a name for yourself by offering these skills to others by becoming a freelancer. There are literally 2000+ new projects that are posted every single freakin' day, no lie!
 Previous Article |  Next Article |