Top 3 Products & Services
| 1. 2. 3. |
Dated: Dec. 12, 2009
Related Categories
Network+ CertificationNetworking In General
This very much to the point guide highlights some important networking terms and topics and simplifies them to us, the mere mortals.
Before we begin, I want to point out that this guide was posted solely due to "SWAP's" request on Suggest a Topic page. If you have a topic you like to suggest, you know where to go.
Let's Begin!....
DNS (Domain Name Service)
The Domain Name System (DNS) is a system that stores information associated with domain names in a distributed database on networks, such as the Internet. The domain name system associates many types of information with domain names, but most importantly, it provides the IP address associated with the domain name. It also lists mail exchange servers accepting e-mail for each domain.
DNS is useful for several reasons. Most well known, the DNS makes it possible to attach hard-to-remember IP addresses (such as 207.142.131.206) to easy-to-remember domain names (such as "") Humans take advantage of this when they recite URLs and e-mail addresses. Less recognized, the domain name system makes it possible for people to assign authoritative names, without needing to communicate with a central registrar each time.
The domain name space is a gigantic tree of domain names. Each node or leaf in the tree is associated with resource records, which hold the information associated with the domain name. The tree is divided into zones. A zone is a collection of connected nodes that are authoritatively served by an authoritative DNS nameserver. (Note that a single nameserver can host several zones.)
When a system administrator wants to let another administrator control a part of the domain name space within his or her zone of authority, he or she can delegate control to the other administrator. This splits a part of the old zone off into a new zone, which is served by the second administrator's nameservers. The old zone is no longer authoritative for what is under the authority of the new zone.
The information associated with nodes is looked up by a resolver. A resolver knows how to communicate with name servers by sending DNS requests, and heeding DNS responses. Resolving usually entails recursing through several name servers to find the needed information. Some resolvers are simple, and can only communicate with a single ame server. These simple resolvers rely on a recursing name server to perform the work of finding information for it.
Important categories of data stored in the DNS include an A record or address record maps a hostname to its 32-bit IPv4 address, an AAAA record or IPv6 address record maps a hostname to its 128-bit IPv6 address, a CNAME record or canonical name record makes one domain name an alias of another. The aliased domain gets all the subdomains and DNS records of the original, an MX record or mail exchange record maps a domain name to a list of mail exchange servers for that domain, a PTR record or pointer record maps an IPv4 address to the canonical name for that host. Setting up a PTR record for a hostname in the in-addr.arpa domain that corresponds to an IP address implements reverse DNS lookup for that address. For example (at the time of writing), www.icann.net has the IP address 192.0.34.164, but a PTR record maps 164.34.0.192.in-addr.arpa to its canonical name, referrals.icann.org., an NS record or name server record maps a domain name to a list of DNS servers for that domain. Delegations depend on NS records, an SOA record or start of authority record specifies the DNS server providing authoritative information about an Internet domain, an SRV record is a generalized service location record, a TXT record allows an administrator to insert arbitrary text into a DNS record. For example, this record is used to implement the Sender Policy Framework specification.
 SMTP (Simple Mail Transfer Protocol)
SMTP (Simple Mail Transfer Protocol)
Simple Mail Transfer Protocol (SMTP) is the de facto standard for email transmission across the Internet. SMTP is a relatively simple, text-based protocol, where one or more recipients of a message are specified (and in most cases verified to exist) and then the message text is transferred. It is quite easy to test a SMTP server using the telnet program. SMTP uses TCP port 25. To determine the SMTP server for a given domain name, the MX (Mail eXchange) DNS record is used. SMTP started becoming widely used in the early 1980s. At the time, it was a complement to UUCP which was better suited to handle e-mail transfers between machines that were intermittently connected. SMTP, on the other hand, works best when both the sending and receiving machines are connected to the network all the time. Send mail was one of the first (if not the first) mail transfer agents to implement SMTP. As of 2001 there are at least 50 programs that implement SMTP as a client (sender of messages) or a server (receiver of messages). Some other popular SMTP server programs include Philip Hazel's exim, IBM's Postfix, D. J. Bernstein's qmail, and Microsoft Exchange Server.
This protocol started out as purely ASCII text-based, it did not deal well with binary files. Standards such as MIME were developed to encode binary files for transfer through SMTP. Today, most SMTP servers support the 8BITMIME extension, permitting binary files to be transmitted almost as easily as plain text.
SMTP is a "push" protocol that does not allow one to "pull" messages from a remote server on demand. To do this a mail client must use POP3 or IMAP. Another SMTP server can trigger a delivery in SMTP using ETRN.
One of the limitations of the original SMTP is that it has no facility for authentication of senders. Therefore the SMTP-AUTH extension was defined.
In spite of this, E-mail spamming is still a major problem. Modifying SMTP extensively, or replacing it completely, is not believed to be practical, due to the network effects of the huge installed base of SMTP. Internet Mail 2000 is one such proposal for replacement.For this reason, there are a number of proposals for sideband protocols that will assist SMTP operation. The Anti-Spam Research Group of the IRTF is working on a number of Email authentication and other proposals for providing simple source authentication that is flexible, lightweight, and scalable.
After establishing a connection between the sender (the client) and the receiver (the server), the following is a legal SMTP session. In the following conversation, everything sent by the client is prefaced with "C:" and everything sent by the server is prefaced with "S:". On most computer systems, a connection can be established using the telnet command on the sending machine, for example telnet www.example.com 25 which opens an SMTP connection from the sending machine to the host www.example.com.
S: 220 www.example.com ESMTP Postfix
C: HELO mydomain.com
S: 250 Hello mydomain.com
C: MAIL FROM:
S: 250 Ok
C: RCPT TO:
S: 250 Ok
C: DATA
S: 354 End data with .
C: Subject: test message
C: From: sender@mydomain.com
C: To: friend@example.com
C:
C: Hello.
C: This is a test.
C: Goodbye.
C: .
S: 250 Ok: queued as 12345
C: QUIT
S: 221 Bye
Although optional and not shown above, nearly all clients ask the server which SMTP extensions the server supports by using the EHLO greeting. These clients use HELO only if the server does not respond to EHLO.
 HTTP (HyperText Transfer Protocol)
HTTP (HyperText Transfer Protocol)
HyperText Transfer Protocol (HTTP) is the primary method used to convey information on the World Wide Web. The original purpose was to provide a way to publish and receive HTML pages. Development of HTTP was coordinated by the World Wide Web Consortium and working groups of the Internet Engineering Task Force, culminating in the publication of a series of RFCs, most notably RFC 2616, which defines HTTP/1.1, the version of HTTP in common use today.
HTTP is a request/response protocol between clients and servers. An HTTP client, such as a web browser, typically initiates a request by establishing a TCP connection to a particular port on a remote host (port 80 by default). An HTTP server listening on that port waits for the client to send a request string, such as "GET / HTTP/1.1" (which would request the default page of that web server), followed by an email-like MIME message which has a number of informational header strings that describe aspects of the request, followed by an optional body of arbitrary data. Some headers are optional, while others (such as Host) are required by the HTTP/1.1 protocol. Upon receiving the request, the server sends back a response string, such as "200 OK", and a message of its own, the body of which is perhaps the requested file, an error message, or some other information.
Resources used in the HTTP are identified using Uniform Resource Identifiers (URIs) in the http or https schemes.
In HTTP/0.9 and HTTP/1.0, a client sends a request to the server and then the server sends a response back to the client. After this, the connection is closed. HTTP/1.1, however, supports persistent connections. This enables the client to send a request and get a response, and then send additional requests and get additional responses. The TCP connection is not released for the multiple additional requests, so the relative overhead due to TCP is much less per request. The use of persistent connection is often called keep alive. It is also possible to send more than one (usually between two and five) request before getting responses from previous requests. This is called pipelining.
There is a HTTP/1.0 extension for connection persistence, but its utility is limited due to HTTP/1.0's lack of unambiguous message delimition rules. This extension uses a header called Keep-Alive, while the HTTP/1.1 connection persistence uses the Connection header. Therefore a HTTP/1.1 may choose to support either just HTTP/1.1 connection persistence, or both HTTP/1.0 and HTTP/1.1 connection persistence. Some HTTP/1.1 clients and servers do not implement connection persistence or have it disabled in their configuration.Both HTTP servers and clients are allowed to close TCP/IP connections at any time (i.e. depending on their settings, their load, etc.). This feature makes HTTP ideal for the World Wide Web, where pages regularly link to many other pages on the same server or to external servers. Closing an HTTP/1.1 connection can be a much longer operation (from 200 milliseconds up to several seconds) than closing an HTTP/1.0 connection, because the first usually needs a linger close while the second can be immediately closed as soon as the entire first request has been read and the full response has been sent.
HTTP can occasionally pose problems for Web developers (Web Applications), because HTTP is stateless (i.e. it does not keep session information) so this "feature" forces the use of alternative methods for maintaining users' "state". Many of these methods involve the use of cookies. HTTP is a URI scheme equivalent to the http scheme. It signals the browser to use HTTP with added encryption layer of SSL/TLS to protect the traffic. SSL is especially suited for HTTP since it can provide some protection even if only one side to the communication is authenticated. In the case in HTTP transactions over the Internet, typically only the server side is authenticated.
FTP (File Transfer Protocol)
FTP or file transfer protocol is a protocol used for exchanging files over the Internet. FTP works in the same way as HTTP for transferring Web pages from a server to a user's browser, and SMTP for transferring electronic mail across the Internet in that FTP uses the Internet's TCP/IP protocols to enable data transfer. FTP is most commonly used to download a file from a server using the Internet or to upload a file to a server (e.g., uploading a Web page file to a server). While data is being transferred across the data stream, the control stream does not do anything. This can cause problems with large data transfers through a firewall, which will time out sessions after long periods of idleness. While the file may well be successfully transferred, the control session can be disconnected by the firewall, causing an error. FTP requires the user to login before data transfer can occur. However, anonymous access is also popular.
FTP is commonly run on two ports, 20 and 21. FTP can run over TCP as well as UDP, although TCP is much more common.
The FTP Server listens on Port 21 for incoming connection from FTP clients. A connection on this port forms the control stream, on which commands are passed to the FTP server.
For the actual file transfer to take place, a different connection is required. Depending on the transfer mode, the client (passive mode) or the server (active mode) can listen for the incoming data connection. Before file transfer begins, the client and server also negotiate the Port of the Data connection. In case of active connections, (where the server connects to the client to transfer data) the server binds on Port 20 before connecting to the client. For passive connections, there is no such restriction.
While data is being transferred via the data stream, the control stream sits idle. This can cause problems with large data transfers through firewalls which time out sessions after lengthy periods of idleness. While the file may well be successfully transferred, the control session can be disconnected by the firewall, causing an error to be generated.
The objectives of FTP, as outlined by its RFC, are to promote sharing of files (computer programs and/or data), to encourage indirect or implicit use of remote computers, to shield a user from variations in file storage systems among different hosts, to transfer data reliably and efficiently.
Disadvantages are passwords and file contents are sent in clear text in which can be intercepted by eavesdroppers, multiple TCP/IP connections are used in which one for the control connection and one for each download and upload, it is hard to filter active mode FTP traffic on the client side by using a firewall since the client must open an arbitrary port in order to receive the connection and this problem is largely resolved by using passive mode FTP, it is possible to abuse the protocol's built-in proxy features to tell a server to send data to an arbitrary port of a third computer, FTP is an extremely high latency protocol due to the number of commands needed to initiate a transfer, FTP is designed mainly for use by FTP client programs although is usable directly by a user at a terminal. Many sites that run FTP servers enable so-called "anonymous ftp". Under this arrangement, users do not need an account on the server. By default, the account name for the anonymous access is 'anonymous'. This account does not need a password. Users are commonly asked to send their email addresses as their passwords for authentication, usually there is trivial or no verification, depending on the FTP server and its configuration.
 Hub
Hub
An Ethernet hub or concentrator is a device for connecting multiple twisted pair or fiber optic Ethernet devices together, making them act as a single segment. It works at the physical layer of the OSI model, repeating the signal that comes into one port out each of the other ports. If a signal comes into two ports at the same time a collision occurs, so every attached device shares the same collision domain. Hubs support only half duplex Ethernet, providing bandwidth which is shared among all the connected devices.
Most hubs detect typical problems such as excessive collisions on individual ports, and partition the port, disconnecting it from the shared medium. Thus hub-based Ethernet is generally more robust than coaxial cable based Ethernet where a misbehaving device can disable the entire segment. Even if not partitioned automatically, a hub makes troubleshooting easier because status lights can indicate the possible problem source or, as a last resort, devices can be disconnected from a hub one at a time much more easily than a coaxial cable.
Although switches are much more common, hubs are still useful in special circumstances:-A protocol analyzer connected to a switch does not always receive all the desired packets since the switch separates the ports into different segments. Connecting it to a hub allows it to see all the traffic going through the hub.
Some computer clusters require each member computer to receive all of the traffic going to the cluster. A hub will do this naturally; using a switch requires implementing special tricks.
When a switch is accessible for end users to make connections (for example, in a conference room), an inexperienced or careless user (or saboteur) can bring down the network by connecting two ports together, causing a loop. This can be prevented by using a hub, where a loop will break other users on the hub but not the rest of the network.
 Switch
Switch
A switch is a device for making or breaking an electric circuit, or for selecting between multiple circuits. In the simplest case, a switch has two pieces of metal called contacts that touch to make a circuit, and separate to break the circuit. The contact material is chosen for its resistance to corrosion, because most metals form insulating oxides that would prevent the switch from working. Sometimes the contacts are plated with noble metals. They may be designed to wipe against each other to clean off any contamination. Nonmetallic conductors, such as conductive plastic, are sometimes used. The moving part that applies the operating force to the contacts is called the actuator, and may be a toggle or dolly, a rocker, a push-button or any type of mechanical linkage
A pair of contacts is said to be 'closed' when there is no space between them, allowing electricity to flow from one to the other. When the contacts are separated by a space, they are said to be 'open', and no electricity can flow. Switches can be classified according to the arrangement of their contacts. Some contacts are normally open until closed by operation of the switch, while others are normally closed and opened by the switch action. A switch with both types of contact is called a changeover switch. The terms pole and throw are used to describe switch contacts. A pole is a set of contacts that belong to a single circuit. A throw is one of two or more positions that the switch can adopt. These terms give rise to abbreviations for the types of switch which are used in the electronics industry. In mains wiring names generally involving the word way are used; however, these terms differ between British and American English and the terms two way and three way are used in both with different meanings. Switches with larger numbers of poles or throws can be described by replacing the "S" or "D" with a number or in some cases the letter T (for triple). In the rest of this article the terms SPST SPDT and intermediate will be used to avoid the ambiguity in the use of the word "way".
In a multi-throw switch, there are two possible transient behaviors as you move from one postion to another. In some switch designs, the new contact is made before the old contact is broken. This is known as make-before-break, and ensures that the moving contact never sees an open circuit. The alternative is break-before-make, where the old contact is broken before the new one is made. This ensures that the two contacts are never shorted to each other. Both types of design are in common use, for different applications
A biased switch is one containing a spring that returns the actuator to a certain position. The "on-off" notation can be modified by placing parentheses around all positions other than the resting position. For example, an (on)-off-(on) switch can be switched on by moving the actuator in either direction away from the centre, but returns to the central off position when the actuator is released.The momentary push-button switch is a type of biased switch. The most common type is a push-to-make switch, which makes contact when the button is pressed and breaks when the button is released. A push-to-break switch, on the other hand, breaks contact when the button is pressed and makes contact when it is released. An example of a push-to-break switch is a button used to release a door held open by an electromagnet. Changeover push button switches do exist but are even less common.
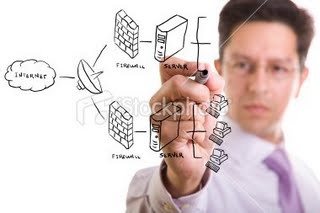 Firewall
Firewall
Today, firewalls are again using application level filters called proxies - or application level proxies because machines with modern CPU speeds are capable of doing deep inspection in reasonable time. These proxies can read the data part of each packet in order to make intelligent decisions about the connection. For example, http can be used to tunnel IRC or peer to peer file sharing protocols. Traditional stateful firewalls cannot detect this while an application level firewall can detect and selectively block http connections according to content.
Modern computers typically exchange data by breaking it up to network frames. These frames are called "packets" in TCP/IP, the most commonly used network protocol. Firewalls inspect each packet and decide whether it should be allowed to pass the firewall and continue travelling towards its destination, or discarded. Common ways of filtering packets are according to the source/destination address or according to the source/destination port.
But in most cases this information is not enough. The administrator of the firewall might want to allow packets to pass the firewall according to the context of the connection, and not just the individual packet characteristics. Therefore, a packet belonging to an existing connection, aimed at port 22 (the Secure Shell port) should be allowed to pass the firewall, but a packet that does not belong to any existing connection must be dropped.
With the traditional stateless firewalls, this was a problem, since the firewall had no way of knowing which packets belonged to existing connections and which didn't. Stateful firewalls solve this problem by monitoring network connections and matching any packets they inspect to existing or new connections. Therefore, they offer more fine grained control over network traffic.
Packet-filter Firewall- firewall can be used as a packet filter. It can forward or block packets based on the information in the network layer and transport layer headers: source and destination IP addresses, source and destination port addresses, and type of protocol (TCP or UDP). A packet-filter firewall is a router that uses a filtering table to decide which packets must be discarded (not forwarded).
Proxy Firewall- The packet-filter firewall is based on the information available in the network layer and transport layer headers (IP and TCP/UDP). However, sometimes we need to filter a message based on the information available in the message itself (at the application layer). As an example, assume that an organization wants to implement the following policies regarding its Web Pages: Only those Internet users who have previously established business relations with the company can have access; access to other users must be blocked. In this case, a packet-filter firewall is not feasible because it cannot distinguish between different packets arriving at TCP port 80 (HTTP). Testing must be done at the application level (using URLs). One solution is to install a proxy computer, which stands between the customer computer and the corporation computer.
BOOTP
In computing, BOOTP, short for Bootstrap Protocol, is a UDP network protocol used by a network client to obtain its IP address automatically. This is usually done in the bootstrap process of computers or operating systems running on them. The BOOTP servers assign the IP address from a pool of addresses to each client. The protocol was originally defined in RFC 951.
BOOTP enables 'diskless workstation' computers to obtain an IP address prior to loading any advanced operating system. Historically, it has been used for Unix-like diskless workstations which also obtained the location of their boot image using this protocol and also by corporations to roll out a pre-configured client installation to newly purchased PCs.
Originally requiring the use of a boot floppy disk to establish the initial network connection, the protocol became embedded in the BIOS of some network cards themselves and in many modern motherboards thus allowing direct network booting.
Recently those with an interest in diskless stand-alone media center PCs have shown new interest in this method of booting a Windows operating system. DHCP is a more advanced protocol based on BOOTP, but is far more complex to implement. Most DHCP servers also offer BOOTP support.
DHCP
Dynamic Host Configuration Protocol (DHCP) is a client-server networking protocol. A DHCP server provides configuration parameters specific to the DHCP client host requesting, generally, information required by the client host to participate on an IP network. DHCP also provides a mechanism for allocation of IP addresses to client hosts. DHCP appeared as a standard protocol in October 1993. RFC 2131 provides the latest (March 1997) DHCP definition. The latest standard on a protocol describing DHCPv6, DHCP in a IPv6 environment, was published in July 2003 as RFC 3315
The DHCP protocol provides three methods of IP-address allocation:
Manual Allocation, where the DHCP server performs the allocation based on a table with MAC address - IP address pairs manually filled by the server administrator. Only requesting clients with a MAC address listed in this table get the IP address according to the table. Automatic Allocation, where the DHCP server permanently assigns to a requesting client a free IP-address from a range given by the administrator. Dynamic Allocation, the only method which provides dynamic re-use of IP addresses. A network administrator assigns a range of IP addresses to DHCP, and each client computer on the LAN has its TCP/IP software configured to request an IP address from the DHCP server when that client computer's network interface card starts up. The request-and-grant process uses a lease concept with a controllable time period. This eases the network installation procedure on the client computer side considerably. Some DHCP server implementations can update the DNS name associated with the client hosts to reflect the new IP address. They make use of the DNS update protocol established with RFC 2136
DHCP is used by most cable internet in the U.S. to allocate IP addresses. DSL providers in the US rarely use DHCP, using PPPoE instead. In addition, several routers provide DHCP support for networks of up to 255 computers, for assigning private IP addresses.
Microsoft introduced DHCP on their NT server with Windows NT version 3.5 in late 1994. Despite being called "a new feature from Microsoft", DHCP did not originate from Microsoft. The Internet Software Consortium published DHCP software distributions for Unix variants with version 1.0.0 of the ISC DHCP Server released on December 6, 1997 and a more RFC-compliant version 2.0 on June 22, 1999. One can download this software from http://www.isc.org/sw/dhcp/Novell has included a DHCP server in their NetWare operating system since version 5, released in 1998. It integrates with Novell's directory service - Novell eDirectory. Other major implementations include:
Cisco with a DHCP server made available in Cisco IOS 12.0 in February 1999 Sun, who added DHCP support in the July 2001 release of Solaris 8. Cisco Systems offers DHCP servers in routers and switches with their IOS software. Moreover, they offer Cisco Network Registrar (CNR) - a highly scalable and flexible DNS, DHCP and TFTP server.
SNMP
The Simple Network Management Protocol (SNMP) forms part of the internet protocol suite as defined by the Internet Engineering Task Force. The protocol can support monitoring of network-attached devices for any conditions that warrant administrative attention. The SNMP protocol is extensible by design. This is achieved through the notion of a management information base or MIB, which specifies the management data of a specific subsystem of an SNMP-enabled device, using a hierarchical namespace containing object identifiers, implemented via ASN.1. The MIB hierarchy can be depicted as a tree with a nameless root, the levels of which are assigned by different organizations. This model permits management across all layers of the OSI reference model, extending into applications such as databases, email, and the J2EE reference model, as MIBs can be defined for all such area-specific information and operations.
Architecturally, the SNMP framework has three fundamental components: Master Agents, Subagents and Management Stations.
A master agent is a piece of software running on an SNMP-capable network component (say, a router). that responds to SNMP requests made by a management station. Thus it acts as a server in client-server architecture terminology or as a daemon in operating system terminology. A master agent relies on subagents to provide information about or management of specific functionality. Master agent can also be referred as Managed objects. A subagent is a piece of software running on an SNMP-capable network component that implements the information and management functionality defined by a specific MIB / of a specific subsystem like, for example, the ethernet link layer. Some capabilities of the subagent are gathering of information from the managed objects, configuring parameters of the managed object, responding to manager's request and generates alarm, or rather called traps to managers. The manager or management station is the final component in the architecture of SNMP. It functions as the equivalent of a client in a client-server architecture. It issues requests for management operations on behalf of an administrator or application, and receives traps from agents as well.
The SNMP protocol operates at the application layer (layer 7) of the OSI model. It specified (in version 1) five core protocol data units (PDUs):
Normally, a network management system is able to manage device with SNMP agent installed. However in the absence of the SNMP agent, it can be managed with the help of a proxy agent. The SNMP agent associated with the proxy policy is called a proxy agent, or commercially a proxy server. The proxy agent monitor non-SNMP Community with non-SNMP agents and then converts the objects and data to SNMP compatible objects and data tobe fed to an SNMP manager.
IPv4 & IPv6
IPv6 was recommended by the IPv6 Area Directors of the Internet Engineering Task Force at the Toronto IETF meeting on July 25, 1994, and documented in RFC 1752, "The Recommendation for the IP Next Generation Protocol". The recommendation was approved by the Internet Engineering Steering Group on November 17, 1994 and made a Proposed Standard.
The current version of the Internet Protocol is version 4 referred to as IPv4. IPv6 is a new version of IP which is designed to be an evolutionary step from IPv4. It is a natural increment to IPv4. It can be installed as a normal software upgrade in internet devices and is interoperable with the current IPv4. Its deployment strategy was designed to not have any "flag" days. IPv6 is designed to run well on high performance networks such as ATM and at the same time is still efficient for low bandwidth networks such as wireless. In addition, it provides a platform for new internet functionality that will be required in the near future. Pv6 was designed to take an evolutionary step from IPv4. It was not a design goal to take a radical step away from IPv4. Functions which work in IPv4 were kept in IPv6. Functions which didn't work were removed. The changes from IPv4 to IPv6 fall primarily into the following categories:
Expanded Routing and Addressing Capabilities IPv6 increases the IP address size from 32 bits to 128 bits, to support more levels of addressing hierarchy and a much greater number of addressable nodes, and simpler auto-configuration of addresses. The scalability of multicast routing is improved by adding a "scope" field to multicast addresses.
A new type of address called a "anycast address" is defined, to identify sets of nodes where a packet sent to an anycast address is delivered to one of the nodes. The use of anycast addresses in the IPv6 source route allows nodes to control the path which their traffic flows.
Header Format Simplification Some IPv4 header fields have been dropped or made optional, to reduce the common-case processing cost of packet handling and to keep the bandwidth cost of the IPv6 header as low as possible despite the increased size of the addresses. Even though the IPv6 addresses are four time longer than the IPv4 addresses, the IPv6 header is only twice the size of the IPv4 header.
Improved Support for Options Changes in the way IP header options are encoded allows for more efficient forwarding, less stringent limits on the length of options, and greater flexibility for introducing new options in the future.
Quality-of-Service Capabilities A new capability is added to enable the labeling of packets belonging to particular traffic "flows" for which the sender requests special handling, such as non-default quality of service or "real- time" service.
Authentication and Privacy Capabilities IPv6 includes the definition of extensions which provide support for authentication, data integrity, and confidentiality. This is included as a basic element of IPv6 and will be included in all implementations.
The IPv6 protocol consists of two parts, the basic IPv6 header and IPv6 extension headers.
There are a number of reasons why IPv6 is appropriate for the next generation of the Internet Protocol. It solves the Internet scaling problem, provides a flexible transition mechanism for the current Internet, and was designed to meet the needs of new markets such as nomadic personal computing devices, networked entertainment, and device control. It does this in a evolutionary way which reduces the risk of architectural problems.
Ease of transition is a key point in the design of IPv6. It is not something was added in at the end. IPv6 is designed to interoperate with IPv4. Specific mechanisms were built into IPv6 to support transition and compatibility with IPv4. It was designed to permit a gradual and piecemeal deployment with a minimum of dependencies.
IPv6 supports large hierarchical addresses which will allow the Internet to continue to grow and provide new routing capabilities not built into IPv4. It has anycast addresses which can be used for policy route selection and has scoped multicast addresses which provide improved scalability over IPv4 multicast. It also has local use address mechanisms which provide the ability for "plug and play" installation.
The address structure of IPv6 was also designed to support carrying the addresses of other internet protocol suites. Space was allocated in the addressing plan for IPX and NSAP addresses. This was done to facilitate migration of these internet protocols to IPv6.
IPv6 provides a platform for new Internet functionality. This includes support for real-time flows, provider selection, host mobility, end-to- end security, auto-configuration, and auto-reconfiguration.
In summary, IPv6 is a new version of IP. It can be installed as a normal software upgrade in internet devices. It is interoperable with the current IPv4. Its deployment strategy was designed to not have any "flag" days. IPv6 is designed to run well on high performance networks such as ATM and at the same time is still efficient for low bandwidth networks such as wireless. In addition, it provides a platform for new internet functionality that will be required in the near future.
Now that you've gotten free know-how on this topic, try to grow your skills even faster with online video training. Then finally, put these skills to the test and make a name for yourself by offering these skills to others by becoming a freelancer. There are literally 2000+ new projects that are posted every single freakin' day, no lie!
 Previous Article |  Next Article |

